17 things that broke getting the first tenant cluster running on Aether
I am building a managed Kubernetes platform from scratch on Proxmox with Kamaji, Talos and Cilium. Getting the first tenant worker to join took two days and 17 things broke along the way. Here is what went wrong and how I fixed it.

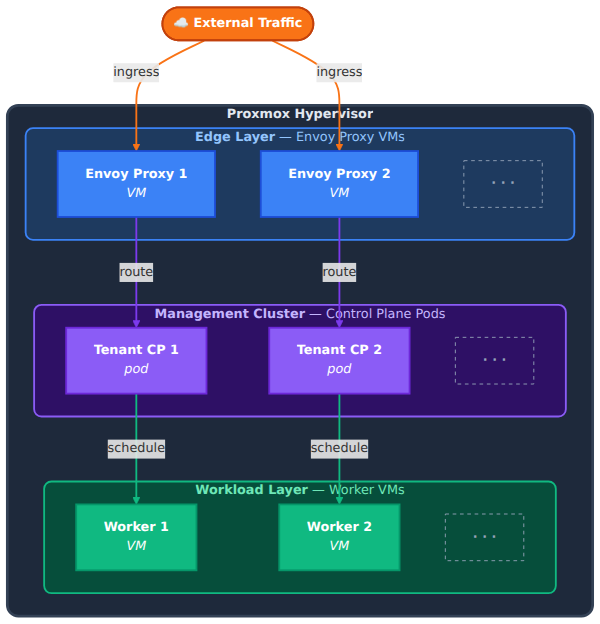
I am building a managed Kubernetes platform called Aether. The idea is that tenants get a kubeconfig and a working cluster and never have to think about the infrastructure underneath. Control planes run as pods via Kamaji, each tenant gets a dedicated Envoy proxy VM, worker nodes run Talos Linux with no shell and no SSH, and everything is provisioned through a custom CAPI provider that talks directly to the Proxmox API.
That is the architecture. What follows is the reality of making it work. Getting the first tenant worker to join the cluster took two full days and I hit 17 distinct problems along the way. Some were trivial, some had me staring at tcpdump output for hours. I am writing this because most blog posts about building platforms skip the ugly parts and I think the ugly parts are where you actually learn something.
Starting point
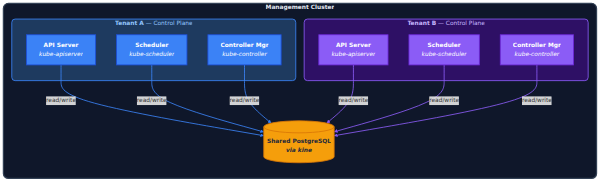
The management cluster was already running. Talos v1.12.6, Kubernetes v1.35.0, Cilium v1.19.2, Kamaji with CloudNativePG backing it, ArgoCD managing everything through git. The first TenantControlPlane demo-cluster was healthy with all four pods running. On paper the next step was simple: provision a worker VM, join it to the tenant cluster, deploy Cilium as CNI.
The Envoy redesign that happened first
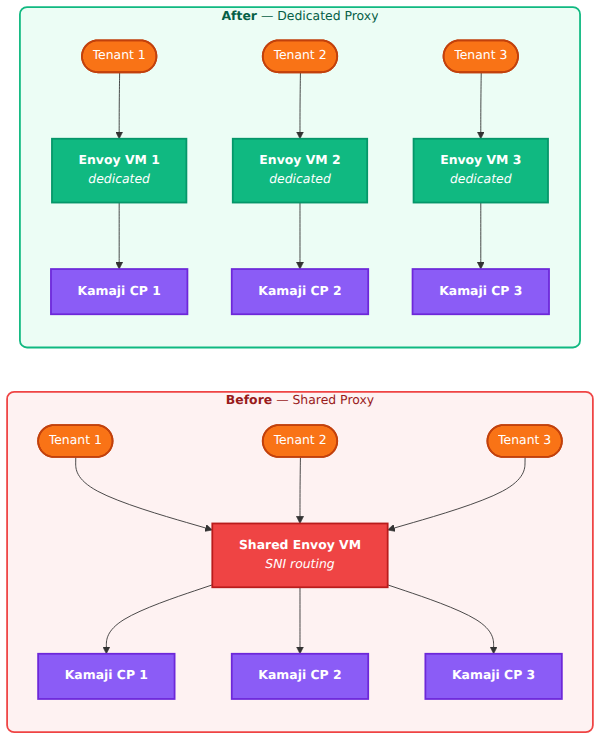
Before I could even think about workers I had to fix the load balancer architecture. The original design was a shared Envoy VM that would route all tenant API server traffic using SNI. One proxy for all tenants, nice and simple.
I threw that out. If that single proxy goes down every tenant loses access to their cluster. And if I want per-tenant source IP filtering or rate limiting, doing that on shared infrastructure is a mess. So I redesigned it to one Envoy proxy VM per tenant. More VMs but each tenant is completely isolated from the others.
I built the Envoy VM template directly on the Proxmox host using qm tooling after GitHub Actions with Packer failed due to TCG and cloud-init issues in the CI environment. The template ended up being Debian 12 with Envoy 1.33.0, dual NIC, systemd services for Envoy and a config-watcher agent, and SSH removed entirely.
Why I ditched CAPX and wrote my own provider
I initially deployed CAPX (the Cluster API Provider for Proxmox) v0.7.7 to handle VM provisioning. It works well for what it is designed for which is provisioning full Kubernetes clusters on Proxmox. But my architecture uses Kamaji for control planes and I only need VM lifecycle management for workers and Envoy LB VMs. CAPX does too much and not exactly what I need.
The specific problems were around cloud-init injection, VMID allocation (I need templates in the 100-999 range and VMs at 1000+), and NIC configuration where I need precise control over ipconfig0 vs ipconfig1 for different bridges. CAPX abstracts all of that away but I need it.
So I wrote aether-controllers. About 1,200 lines of Go with controller-runtime implementing the CAPI Infrastructure Provider contract. AetherCluster, AetherMachine, AetherMachineTemplate CRDs with a direct Proxmox API client. The first version had several bugs that showed up immediately when I tried to deploy it: the CRD group marker was wrong, the image was built for the wrong architecture, the Proxmox node name in the config did not match reality, and the VMID enforcement was not working. Fixed those, tagged v0.1.4, pushed to GHCR.
The LoadBalancer controller and the ipconfig bug
The LB controller watches for Service{type:LoadBalancer} objects, clones the Envoy template, configures the proxy per tenant. It worked in development but when I deployed it the Envoy VM kept getting its IP on the wrong network interface.
The root cause was embarrassing. The code had the correct ipconfig1 for the vmbr1 bridge but the deployed version v0.1.3 still had the old ipconfig0 bug. I had fixed it locally but never tagged and pushed the new image. Built multi-arch, pushed to GHCR, updated ArgoCD, and the Envoy proxy VM 1005 came up at 10.1.1.10 on the correct interface.
ArgoCD going down at the worst time
Right when I needed ArgoCD to deploy the fix, ArgoCD itself was broken. The repo-server pod had a stuck copyutil init container with an "Already exists" error and every app was showing Unknown sync status.
Deleting the pod fixed it temporarily but then I hit the next problem. All my app manifests were using https://github.com/...URLs but the repository credentials were configured for git@github.com:... SSH access. ArgoCD could not authenticate. I had to change all five app manifests to SSH URLs, patch the root app in-cluster and resync everything.
The 17 problems joining the first worker
With the Envoy proxy running and ArgoCD back I could finally try joining a worker. Here is where it got interesting. I will list the big ones.
Kubernetes version skew. The worker was running kubelet v1.35.2 from the Talos v1.12.6 image but the tenant control plane was v1.30.2 via Kamaji. That is five minor versions apart which is unsupported. The fix was setting kubelet.image: ghcr.io/siderolabs/kubelet:v1.30.2 in the worker machine config to force the right version.
Cluster CA mismatch — this was the root cause of the join failure. The worker machine config had the Kubernetes CA that talosctl generated during initial setup. But Kamaji generates its own separate CA for each tenant. The kubelet was silently failing TLS verification against the API server because it was using the wrong CA. No obvious error, just a connection that would never complete. I replaced cluster.ca.crt in the worker config with the Kamaji-generated CA from the tenant kubeconfig secret and the TLS handshake started working.
KubePrism not starting. KubePrism is the Talos localhost API proxy on port 7445. It depends on apid for endpoint discovery and apid needs trustd to get its certificate signed. But with Kamaji there is no Talos control plane so there is no trustd. KubePrism would never start and kubelet could not reach the API server through localhost. The fix was kubePrism.enabled: false in the worker config and pointing kubelet directly at the control plane endpoint through the Envoy proxy.
Cilium chicken-and-egg. This was a fun one. Cilium's init container tries to reach the Kubernetes API via ClusterIP (10.96.0.1:443). But ClusterIP routing requires the CNI to be running and the CNI is what we are trying to install. Classic deadlock. The fix was setting k8sServiceHost=10.1.1.10 and k8sServicePort=6443 in the Cilium Helm values to bypass ClusterIP and go directly to the Envoy proxy.
Stale ARP cache after VM destroy. After destroying the old broken LB VM 1004, the Proxmox host still had VM 1004's MAC address cached for IP 10.1.1.10. The new Envoy proxy VM got the same IP but packets were being sent to the old MAC. The proxy was completely unreachable until I ran ip neigh flush 10.1.1.10 on the host.
Kamaji advertise-address was wrong. The TenantControlPlane's kube-apiserver had --advertise-address set to its ClusterIP which is unreachable from tenant workers. Workers need to reach it through the Envoy proxy at 10.1.1.10. I patched the Kamaji resource to use the proxy IP and the apiserver started advertising the correct address.
Bootstrap token mismatch. The worker config referenced a bootstrap token that did not exist in the tenant cluster. Kamaji had created its own default token. I had to create a matching bootstrap-token-nzbyod secret in the tenant cluster's kube-system namespace.
There were more: QEMU guest agent not working because the virtio serial port was not enabled on the VM, Talos losing its IP after every reset to maintenance mode due to a known Proxmox cloud-init issue, storage NIC not configured for the Ceph network, Cilium crashing on the management CP after a hard reboot. Each one had its own fix and its own hour of debugging.

The moment it worked
After all of that:
kubectl get nodes
NAME STATUS ROLES AGE VERSION
talos-l08-5er Ready <none> 2m v1.30.2One node, Ready, running v1.30.2 with Cilium as CNI. The first tenant worker on Aether.
What I learned for the provisioning workflow
Most of these problems were one-time discoveries that are now baked into the automated workflow. The key lessons:
Use the Kamaji CA in worker configs, not the talosctl-generated one. Create matching bootstrap tokens in the tenant cluster. Disable KubePrism for Kamaji workers. Pin the kubelet image version to match the tenant CP. Deploy Cilium with explicit k8sServiceHost before provisioning workers. Configure the storage NIC for the Ceph network. Set --agent enabled=1 on all Talos VMs for the QEMU guest agent.
Every one of these is now a step in the automated provisioning path. The next tenant cluster will not hit any of them.
What comes next
The foundation is working. The custom CAPI provider provisions VMs, Kamaji creates control planes as pods, the Envoy proxy routes traffic, Cilium enforces network policy, and workers join and go Ready. Phase 1 is the platform API which is already at 2,790 lines of Go, the observability stack, and the services that make this a real platform — Harbor for container images, Keycloak for OIDC, automated DNS, automated TLS.
I am building Aether because I think managed Kubernetes should mean you get a kubeconfig and everything else is taken care of. Not just a control plane and some nodes with the rest left as an exercise. If you are interested in following along or want to be an early adopter when it launches, subscribe below.